在客户端机器阿航安装 epel 扩展源
1
| yum install -y epel-release
|
安装 nagios 以及 nagios-plugins
1
| yum install -y nagios-plugins nagios-plugins-all nrpe nagios-plugins-nrpe
|
编辑配置文件
1
| vim /etc/nagios/nrpe.cfg
|
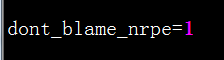
找到 “allowed_hosts=127.0.0.1” 改为 “allowed_hosts=127.0.0.1,192.168.0.62 ” 后面的 ip 为服务端 ip ; 找到 “dont_blame_nrpe=0” 改为 “dont_blam_nrpe=1”

修改为


修改为
启动客户端
客户端配置好以后,在到服务端继续配置。客户端 ip 为 192.168.0.98,下面定义子配置文件。(以下操作在服务端上完成)
1 2
| [root@nagios ~] [root@nagios conf.d]
|
增加配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
| define host{ use linux-server host_name 192.168.0.98 alias 0.98 address 192.168.0.98 } define service{ use generic-service host_name 192.168.0.98 service_description check_ping check_command check_ping!100.0,20%!200.0,50% max_check_attempts 5 normal_check_interval 1 } define service{ use generic-service host_name 192.168.0.98 service_description check_ssh check_command check_ssh max_check_attempts 5 normal_check_interval 1 notification_interval 60 } define service{ use generic-service host_name 192.168.0.98 service_description check_http check_command check_http max_check_attempts 5 normal_check_interval 1 }
|
说明:
- “max_check_attempts 5” :表示当nagios检测到问题时,一共尝试检测5次都有问题才会告警,如果该数值为1,那么检测到问题立即告警
- “normal_check_interval 1”:表示重新检测的时间间隔,单位是分钟,默认是3分钟
- “notification_interval 60”:表示在服务出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟。如果你认为,所有的事件只需要一次通知就够了,可以把这里的选项设为0。
以上服务不依赖于客户端 nrpe 服务,可以想象,在子机电脑上可以使用 ping 或者 telnet 探测远程任何一台机器是否存活、是否开启某个端口或服务。而当想要检测客户端上的某个具体服务的情况时,就需要借助于 nrpe 了,比如想知道客户端机器的负载或磁盘使用情况。
编辑完成配置文件后,检测配置是否有错
再服务端重启一下 nagios 服务
然后在浏览器里访问 nagios ,刷新会发现多出来一台主机,并且多出来三个服务。只不过这三个服务并不是我们想要的,想要监控系统负载,监控磁盘使用率等服务,这时候就要使用 nrpe 服务了。继续在服务端上添加服务。
增加
1 2 3 4
| define command{ command_name check_nrpe command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$ }
|
然后继续编辑
增加内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
| define service{ use generic-service host_name 192.168.0.98 service_description check_load check_command check_nrpe!check_load max_check_attempts 5 normal_check_interval 1 } define service{ use generic-service host_name 192.168.0.98 service_description check_disk_sda1 check_command check_nrpe!check_sda1 max_check_attempts 5 normal_check_interval 1 } define service{ use generic-service host_name 192.168.0.98 service_description check_disk_sda3 check_command check_nrpe!check_sda3 max_check_attempts 5 normal_check_interval 1 }
|
说明:“check_nrpe!check_load” 这里的 check_nrpe 就是在 commands.cfg 刚刚定义的,check_load 是远程主机上的一个检测脚本。
在远程主机上编辑 nrpe.cfg 配置文件
搜索 check_load ,这行就是在服务器上要执行的脚本了。然后把 check_hda1 更改一下:/dev/hds1 改为 ,/dev/sda1 。

修改为

再加一行

客户端上重启一下 nrpe 服务
服务端也重启下 nagios 服务
再到浏览器刷新,会看到又多出来三个服务

稍微等一会就可以查看到具体的状态了。
